Inteligencia artificial, cuantificación y reproducibilidad en capilaroscopia
La IA es ya indisociable de la capilaroscopia. En 2024-2026 han aparecido algoritmos cuantitativos y modelos de aprendizaje automático capaces de clasificar patrones, detectar anomalías estructurales y reducir parte de la variabilidad entre observadores; aun así, su utilidad real depende más de la calidad del etiquetado, del quality assessment, de la validación externa, del número de dedos y campos adquiridos y de la estandarización en cómo reportar, que del número bruto de parámetros o de la complejidad del modelo [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 24].
- La cuantificación no sustituye a la descripción semiológica; la ordena. Los algoritmos más útiles traducen densidad, tamaño, hemorragias y morfología en variables reproducibles que luego se interpretan clínicamente [1, 2, 3, 8, 9].
- El mayor problema que intentan resolver estas herramientas no es la falta de imágenes, sino la subjetividad interobservador, sobre todo al distinguir patrón normal frente a inespecífico, y al graduar patrones esclerodermiformes [3, 4, 5, 8, 9].
- En un protocolo estándar de videocapilaroscopia (NVC, por nailfold videocapillaroscopy), un caso puede generar 32 imágenes, con cuatro campos por dedo en ocho dedos; por eso, la rapidez del análisis y del control de calidad no es ya un "lujo", sino un requisito práctico [22, 24].
- El quality assessment es el filtro más importante del flujo de IA: si una imagen entra desenfocada, mal magnificada o mal posicionada, el clasificador aprende y decide sobre ruido [2, 7, 11, 12, 13].
- Los algoritmos Fast Track y CAPI-Score, junto con la experiencia del capilaroscopista, siguen siendo la referencia práctica: los modelos automáticos deben compararse con observadores bien entrenados, no con lecturas improvisadas [3, 5].
- CAPI-Score y CAPI-Detect representan dos estrategias distintas: CAPI-Score se basa en reglas simples derivadas de variables cuantitativas que pueden contabilizarse manualmente, mientras que CAPI-Detect utiliza aprendizaje automático, incorpora más variables y muestra mejor capacidad discriminativa cuando existe un alto grado de acuerdo entre expertos [8, 9].
- La validación externa es más importante que la métrica interna. Un modelo con área bajo la curva (AUC) o accuracy altas puede, sin embargo, perder valor si cambia el equipo, la población, la calidad de la imagen o el estándar de referencia [7, 8, 9, 10, 14].
- Según los consensos recientes, la IA solo es clínicamente útil si se contextualiza con adquisición estandarizada, control de calidad, potenciales factores de confusión y un informe estructurado [2, 11, 12, 13].
Ruta de aprendizaje
Si quieres entender cuándo la cuantificación y la IA realmente añaden valor, aquí encontrarás sus utilidades, límites y sesgos más relevantes. Te resultará especialmente útil si ya dominas adquisición y calidad y lectura semiológica e informe, porque ningún algoritmo es capaz de compensar una imagen mal adquirida o una lectura clínica débil [1, 2, 3, 11, 12].
Por qué cuantificar
La cuantificación nace de un problema concreto: dos observadores competentes pueden coincidir con facilidad en un patrón claramente esclerodermiforme, pero no siempre en una imagen fronteriza, un estudio de mala calidad o la distinción entre normal e inespecífico [3, 4, 5].
El algoritmo Fast Track de la European Alliance of Associations for Rheumatology (EULAR) ya resumía parte de esa necesidad con un árbol de decisión simple para diferenciar patrón esclerodermiforme frente a no esclerodermiforme, alcanzando estimadores kappa de concordancia muy altos incluso entre participantes con diversos grados de experiencia [3]. Este hecho refuerza una idea práctica: antes de llegar a la IA, la capilaroscopia ya había demostrado que simplificar reglas y armonizar definiciones mejora la reproducibilidad.
El problema de la reproducibilidad no se resuelve solo con más entrenamiento informal. Un estudio multicéntrico de Dinsdale et al demostró que la fiabilidad intra e interobservador de variables como densidad, anchura apical, capilares gigantes o grado de gravedad, aunque razonable, no es perfecta, ni incluso entre expertos [4]. A esto se añade que la formación funciona mejor para algunas tareas que para otras: en el entrenamiento online con Fast Track, la identificación de patrón esclerodermiforme frente a no esclerodermiforme alcanzó una concordancia kappa promedio entre observadores de 0,86, mientras que, sin embargo, diferenciar normal de inespecífico no superó el 0,59 [5].
Así pues, la cuantificación posee dos objetivos distintos. Uno es descriptivo: medir mejor densidad, tamaño o hemorragias. El otro es clasificatorio: convertir esas mediciones en una decisión o una probabilidad. Conviene ser cauto en relación con la capacidad de la IA para lograr este segundo objetivo, y no atribuirle la virtud de la infalibilidad [1, 2, 3, 4, 5, 8, 9].
Qué se está midiendo hoy
Los modelos actuales ya no se limitan a contar capilares. La tendencia es convertir la arquitectura completa del lecho distal en un conjunto de variables continuas y reproducibles [6, 7, 8, 9, 10].
En los trabajos más recientes, los dominios cuantificados incluyen densidad capilar por milímetro, porcentaje de capilares gigantes, porcentaje de capilares anómalos, tortuosidad, hemorragias, tamaño del asa, forma global, formas anormales y variables agregadas de arquitectura [6, 7, 8, 9, 10]. Siguiendo una lógica de reglas secuenciales, CAPI-Score usó puntos de corte para densidad, porcentaje de capilares gigantes y anómalos, tortuosidades y hemorragias [8]. CAPI-Detect amplió el espectro y utilizó 24 variables relacionadas con la arquitectura capilar y extraídas automáticamente, para entrenar un modelo CatBoost [9].
Esta evolución es relevante, porque cambia la naturaleza del dato. Cuando una variable se mide de forma continua, deja de depender tanto del lenguaje subjetivo del observador y se vuelve más comparable entre centros, siempre que la adquisición, el control de calidad y el software sean consistentes [2, 6, 7, 8, 9, 11, 12, 13]. Aun así, por inferencia metodológica, conviene recordar que estos sistemas aprenden a partir de etiquetas de consenso humano y no sobre un gold standard biológico independiente [8, 9, 10].

| Dominio | Qué intenta objetivar | Valor potencial | Límite frecuente |
|---|---|---|---|
| Densidad | Número de capilares por mm en fila distal | Base para clasificación y seguimiento [2, 8, 9] | Depende de qué segmento y cuántos milímetros se analicen |
| Tamaño | Dilataciones y gigantes de forma continua | Reduce subjetividad al llamar “capilar gigante” [6, 7, 8, 9] | Requiere calibración y buena resolución |
| Capilares anómalos | Asas con morfología fuera del rango esperado | Ayuda a diferenciar patrones y gravedad [8, 9] | La definición exacta puede variar entre softwares |
| Hemorragias | Extravasaciones visibles y su distribución | Añaden peso a la clasificación [7, 8] | Muy sensibles al trauma y a factores de confusión locales |
| Arquitectura global | Orden, desorganización, formas anormales y densidad combinada | Permite modelos ML más completos [9, 10] | Riesgo de caja negra si no se explican las variables |
ML, machine learning.
Algoritmos actuales y rendimiento
La bibliografía reciente permite distinguir al menos cuatro niveles de complejidad: reglas clínicas simplificadas, cuantificación automática de fenómenos discretos, algoritmos de reglas cuantitativas y aprendizaje automático más flexible [3, 6, 7, 8, 9, 10].
Fast Track como línea de base
El Fast Track no es IA, pero sigue siendo la herramienta que más sentido tiene en clínica. Su valor reside en que ofrece una regla simple y muy reproducible para separar patrón esclerodermiforme de no esclerodermiforme, con un kappa de Cohen (dos observadores) promedio de 0,94 a 0,96, y un kappa de Light (más de dos observadores) de 0,87 a 0,92 en validaciones EULAR y EUSTAR [3]. Muchos desarrollos posteriores, incluido CAPI-Score, se inspiran explícitamente en esa lógica [8].
Detección automática y validación externa
Antes de clasificar patrones completos, varios grupos abordaron tareas más simples: detectar capilares, medir su tamaño y reconocer hemorragias. En la serie de Gracia-Tello BG et al., las métricas de rendimiento del modelo de clasificación de la propuesta inicial alcanzaron una precisión del 83,84% y un recall del 92,44% para identificar capilares, con un rendimiento más discreto cuando debía clasificar formas o tamaños concretos [6]. La validación externa posterior fue más relevante clínicamente: con consenso de al menos tres expertos, el software predijo correctamente el 75,8% de las imágenes; con consenso de al menos cuatro expertos, la concordancia con el software subió al 87,1%, y el valor predictivo positivo superó el 80% para hemorragias y capilares no alterados, gigantes o anómalos [7].
CAPI-Score
CAPI-Score representa el salto desde la simple detección a la clasificación cuantitativa estructurada. Sobre 851 capilaroscopias y 21.957 imágenes consensuadas por nueve capilaroscopistas, el algoritmo estableció cuatro reglas. La primera, para diferenciar patrón esclerodermiforme frente a no esclerodermiforme, alcanzó una accuracy de 0,88; ésta llegó a 0,82 en relación con las reglas para separar patrones temprano, activo y tardío; y en la regla para distinguir patrón normal de inespecífico quedó en 0,73 [8]. La lectura práctica es clara: la automatización funciona mejor cuando la pregunta es binaria y clínicamente robusta que cuando "obliga" a distinguir categorías vecinas y poco definidas.
CAPI-Detect y otros modelos machine learning
CAPI-Detect amplió la estrategia de CAPI-Score con 24 variables arquitectónicas y un modelo de aprendizaje automático. En 1.780 capilaroscopias analizadas en ciego por tres o cuatro observadores, cuando existía consenso parcial entre ellos, el modelo alcanzó accuracies de 0,912, 0,812 y 0,746 para, respectivamente, distinguir esclerosis sistémica (SSc, por systemic sclerosis) de no SSc, clasificar subpatrones esclerodérmicos y diferenciar patrón normal de inespecífico; pero, si el análisis se limitaba solo a imágenes con consenso total, la accuracy subía hasta 0,910, 0,925 y 0,933 [9]. La mejora frente a CAPI-Score sugiere que existe información morfológica relevante que las reglas manuales simplificadas no captan por completo.
Otros enfoques de IA confirman la tendencia, pero también sus límites. Así, aunque el modelo vision transformer de Garaiman A et al. obtuvo AUCs entre 81,8% y 84,5% para signos microangiopáticos y patrón esclerodermiforme, los reumatólogos entrenados siguieron superándolo en promedio [10]. Y, aunque en un estudio reciente que profundizaba en la clasificación dentro de la esclerosis sistémica se han documentado aciertos superiores al 98%, todavía falta una validación clínica multicéntrica que confirme la utilidad de la propuesta, por otro lado indudablemente prometedora [15].

| Herramienta / enfoque | Qué resuelve | Rendimiento publicado | Lectura práctica |
|---|---|---|---|
| Fast Track [3] | Clasificación manual simple SSc vs no SSc | Kappa media 0,94-0,96; Light’s kappa 0,87-0,92 | Sigue siendo la referencia clínica de simplicidad y fiabilidad |
| Pipeline automático inicial [6] | Detección y clasificación de capilares/hemorragias | Precisión 83,84%; recall 92,44% para identificación de capilares | Útil como paso previo, no como informe final autónomo |
| Validación externa [7] | Reproducibilidad en imágenes de distintos centros | 75,8% de acierto con consenso de expertos ≥3; 87,1% con consenso ≥4 | La validación fuera del centro de origen cambia mucho la confianza |
| CAPI-Score [8] | Clasificación por reglas cuantitativas | Accuracy 0,88; 0,82; 0,73 según la tarea | Muy útil para tareas bien definidas; peor para discernir normal vs. inespecífico |
| CAPI-Detect [9] | Clasificación ML con 24 variables | Accuracy 0,912 / 0,812 / 0,746; hasta 0,933 con consenso completo | Prometedor, pero depende mucho de la calidad del etiquetado |
| Vision transformer [10] | Reconocimiento de cambios microangiopáticos | AUC 81,8%-84,5% | Puede ayudar, pero no reemplaza al experto entrenado |
ML, machine learning; SSc, esclerosis sistémica.
Quality assessment y feedback automático
El paso más injustamente descuidado del flujo de la IA no es la clasificación, sino decidir si la imagen merece ser analizada. En capilaroscopia, una imagen inválida no es simplemente "peor"; puede empujar al algoritmo y al clínico hacia una categoría errónea [2, 11, 12, 13].
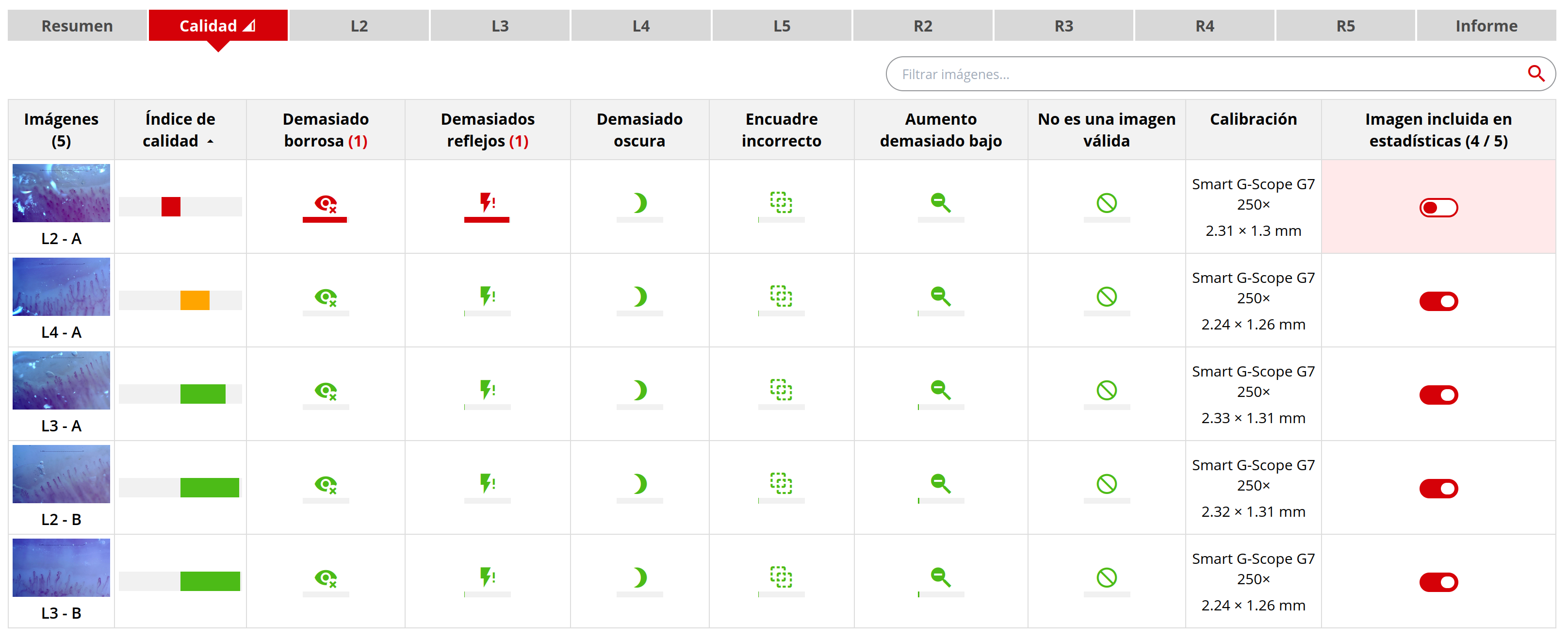
Un abstract del ACR Convergence 2025 (congreso del American College of Rheumatology) sobre Automated Feedback and Quality Control resulta especialmente útil en este contexto. Describe un sistema desarrollado con una arquitectura ConvNeXt V2 y entrenado sobre 10.866 imágenes anotadas, y es capaz de identificar problemas frecuentes de adquisición como baja magnificación, desenfoque, reflejos, posicionamiento incorrecto, infraexposición y contenido inválido; además, para las imágenes válidas diferencia entre calidad baja y calidad aceptable [13]. Los rendimientos reportados fueron especialmente altos en lo que se refiere a identificar (y, por tanto, descartar la imagen en cuestión, o interpretarla con precaución en el último supuesto): baja magnificación (F1-score 0,99); contenido inválido (F1 0,96); desenfoque (F1 0,84); reflejos (F1 0,83); calidad baja dentro de imágenes válidas (F1 0,83) [13].
Este hallazgo es relevante. Un buen flujo de IA en capilaroscopia debería funcionar como una cadena de cuatro eslabones. Primero, adquisición. Segundo, quality assessment para excluir imágenes inválidas y devolver feedback inmediato al operador. Tercero, cuantificación o clasificación solo sobre imágenes aceptables. Cuarto, revisión humana y elaboración del informe. Si se omite el segundo paso, el resto del proceso queda expuesto al clásico problema de garbage in, garbage out [2, 7, 11, 12, 13].
El impacto de este segundo paso se entiende mejor cuando se examina la carga real de trabajo. En un estudio multicéntrico de 2026 centrado en identificar patrones de esclerosis sistémica, la exploración de referencia incluyó 32 imágenes por caso, correspondientes a cuatro campos por dedo en ocho dedos no pulgares [24]. Cuando una plataforma puede analizar la calidad de cada imagen y producir un resumen cuantitativo de la capilaroscopia de forma inmediata, el beneficio no se limita a ahorrar minutos al clínico, por ejemplo evitándole revisar manualmente lotes completos de imágenes defectuosas, ya que, muy importante, le permite repetir la captura en el mismo acto asistencial [13, 22, 24].
El valor del quality assessment no es solo técnico. También es docente. Un sistema que detecta en tiempo real magnificación insuficiente, reflejos o mal posicionamiento puede acelerar el proceso de aprendizaje de residentes o investigadores jóvenes, así como armonizar la captura en estudios multicéntricos, en los que, a menudo, la principal fuente de variación no está en el observador final sino en cómo se obtuvieron las imágenes [7, 11, 12, 13].

| Problema de calidad | Riesgo clínico o algorítmico | Por qué conviene detectarlo antes |
|---|---|---|
| Baja magnificación | Subestima detalle morfológico y sesga la clasificación | Evita analizar una imagen incapaz de mostrar la fila distal con nitidez [13] |
| Desenfoque o reflejos | Falsea bordes, diámetros y hemorragias | Reduce errores de cuantificación y de detección automática [7, 13] |
| Posicionamiento incorrecto | Considera estructuras fuera de la zona útil | Impide calificar como rarefacción un mero problema de encuadre [2, 11, 13] |
| Contenido inválido | Introduce ruido en el modelo | Es el ejemplo más claro de imagen que debe excluirse [13] |
| Imagen válida pero de baja calidad | Puede usarse, pero con menor confianza | Permite decidir si repetirla o interpretarla con cautela |
Capillary.io y líneas publicadas
Entre las plataformas con producción científica visible, Capillary.io merece atención porque permite seguir una misma línea metodológica desde la detección automática inicial hasta modelos de clasificación más complejos, requisitos de muestreo y, más recientemente, herramientas explícitas de quality assessment [6, 7, 8, 9, 13, 19, 20, 24].
Según la página de publicaciones de Capillary.io, la secuencia de publicaciones asociadas a la plataforma incluye un trabajo inicial sobre detección automática y clasificación de capilares y hemorragias [6], una validación clínica externa del software para identificar anomalías estructurales y hemorragias [7], el algoritmo CAPI-Score [8], el modelo de aprendizaje automático CAPI-Detect [9], el estudio de requisitos mínimos de muestreo para clasificar patrón de esclerosis sistémica [24] y la aportación más reciente sobre feedback automático y control de calidad en tiempo real [13, 19]. Este conjunto de aportaciones resulta de gran utilidad, porque no se trata de una única publicación aislada, sino de una cadena de desarrollo que permite valorar la progresión metodológica.
El análisis de estas aportaciones invita a la reflexión. Por un lado, la continuidad editorial permite entender cómo madura una plataforma: primero detecta, luego valida, después clasifica con reglas, finalmente aprende con variables más complejas y, además, intenta controlar la calidad de entrada antes de clasificar [6, 7, 8, 9, 13]. Por otro lado, el hecho de que una misma línea de trabajo genere varias publicaciones no elimina la necesidad de validación independiente, comparación con otros enfoques y demostración, si finalmente se produjera, de utilidad clínica añadida a la aportación del observador experto [7, 8, 9, 10].
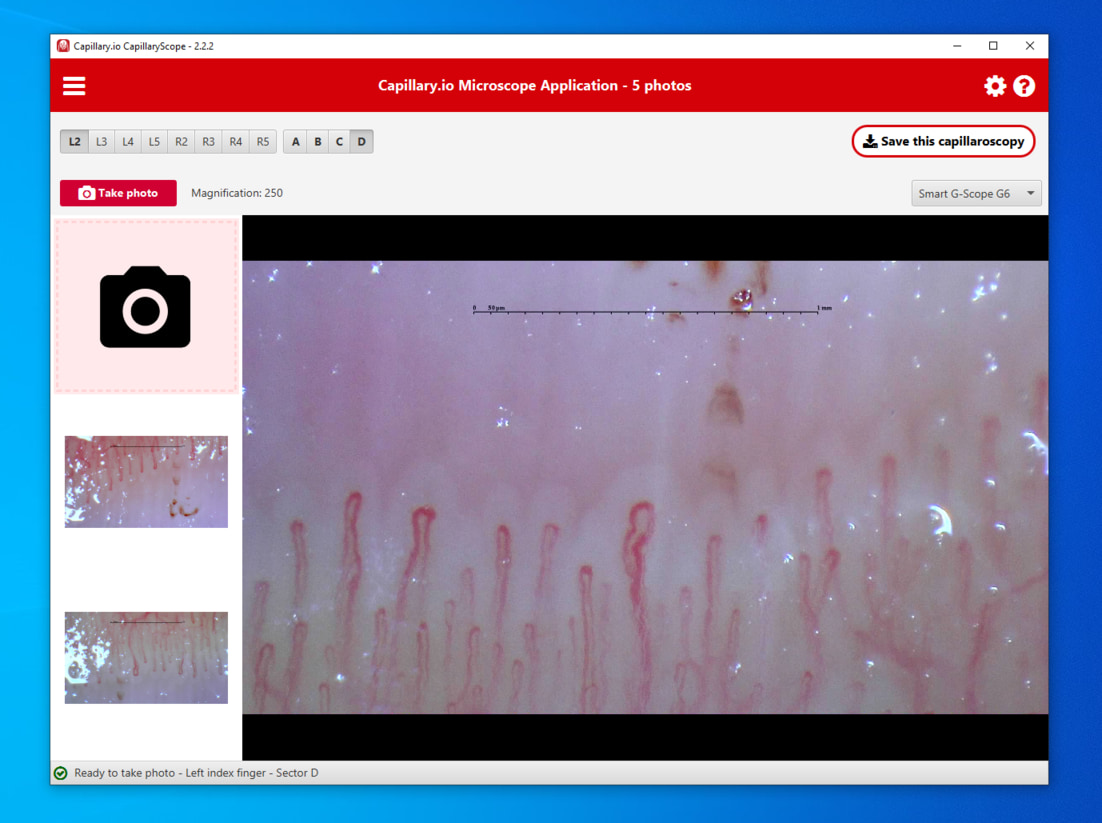
La captura guiada desde app o dispositivo local permite calibrar, ordenar imágenes y enviarlas a la plataforma antes del análisis cuantitativo.
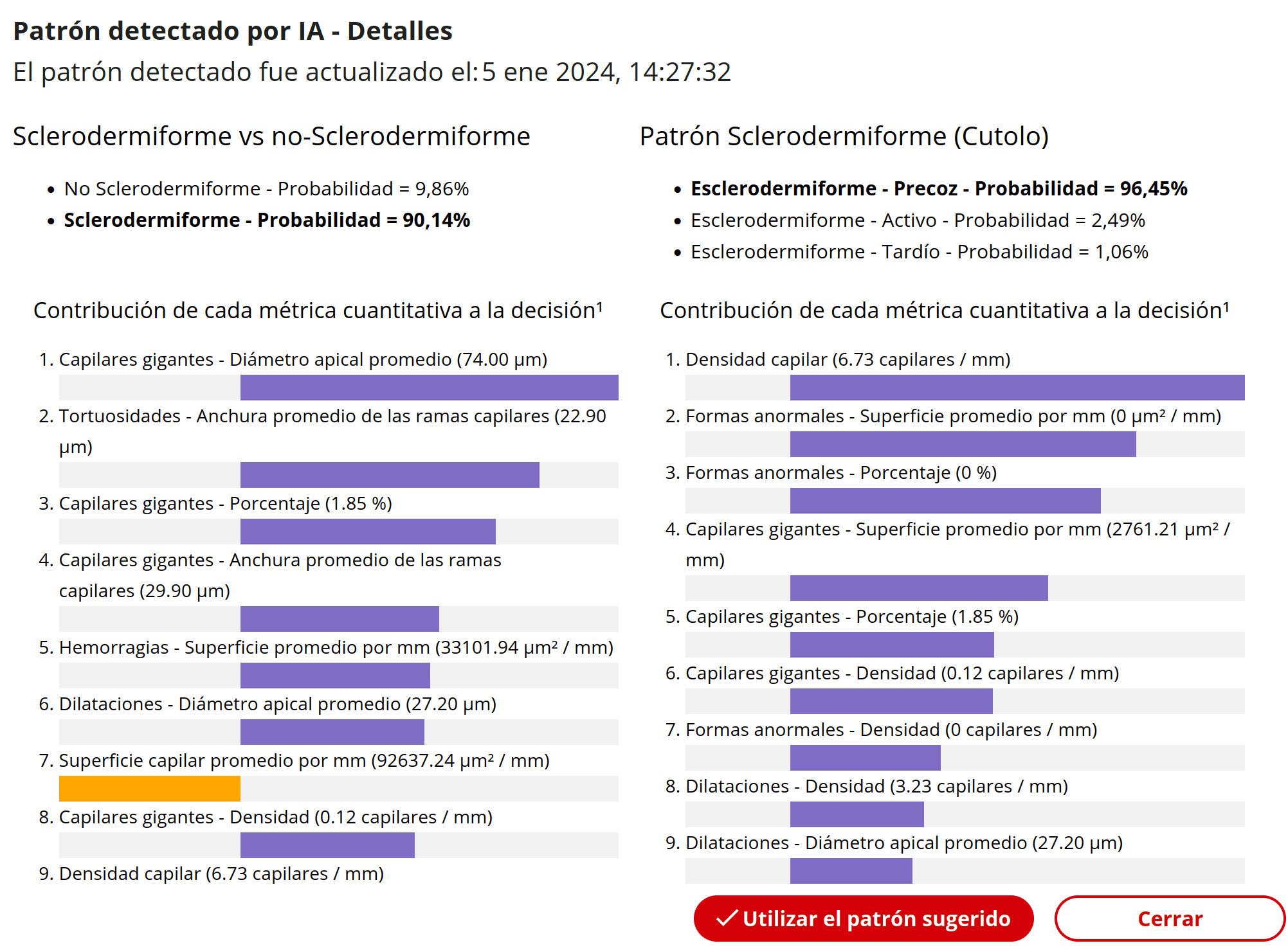
Capillary.io también aparece ya en usos más allá de la esclerosis sistémica clásica. Otra aportación presentada en la citada reunión de ACR 2025 explicaba el empleo de variables cuantitativas extraídas por la plataforma para intentar discriminar fenómeno de Raynaud primario frente a enfermedades autoinmunes dentro del complejo "cajón" de los patrones inespecíficos. El F1-score global obtenido fue 0,632. Aunque el rendimiento era modesto, el estudio es valioso porque permite constatar que el verdadero reto no está tanto en los patrones "claros" como en esa zona gris donde se suscitan más dudas clínicas [14]. En paralelo, el proyecto multicéntrico CapIAMI ya ha presentado datos preliminares en 272 pacientes con miopatías inflamatorias, donde la combinación de métricas capilaroscópicas automatizadas y biomarcadores de laboratorio alcanzó una accuracy de 0,746 para predecir actividad clínica [15, 20].
La expansión continúa hacia escenarios más descriptivos, y hacia el ámbito pediátrico. Otro estudio presentado en ACR 2025 procesó con Capillary.io una cohorte de 136 enfermedades reumáticas autoinmunes para describir "firmas" capilaroscópicas en esclerosis sistémica, poliautoinmunidad e hipertensión pulmonar [16]. También en 2025, un estudio de dermatomiositis juvenil utilizó cuantificación automatizada de densidad y diámetros para relacionar actividad de enfermedad con menor densidad y mayor calibre de asas [17]. Un estudio pediátrico previo demostró que la cuantificación automatizada mediante red neuronal convolucional (CNN) puede agrupar pacientes con dermatomiositis juvenil según morfología capilar y positividad de autoanticuerpos específicos [18]. Vistas en conjunto, estas aportaciones no demuestran que la plataforma esté "validada para todo", sino que más bien nos enseñan cómo la automatización empieza a salir del nicho esclerodérmico y a explorar nuevos fenotipos [14, 15, 16, 17, 18].
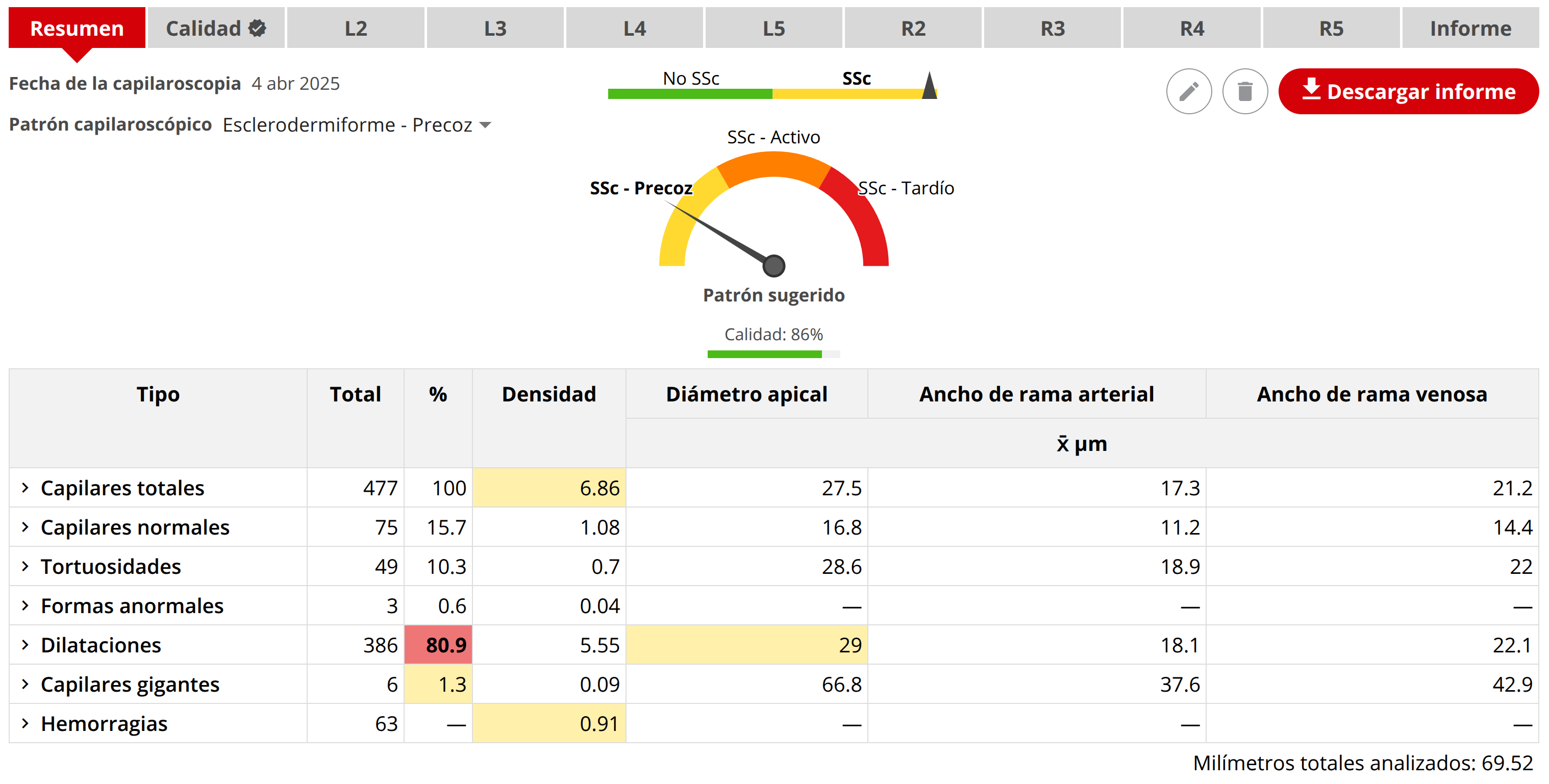
La propia documentación de Capillary.io añade un detalle operativo relevante: una capilaroscopia puede contener múltiples imágenes por dedo, y la plataforma genera entonces un informe cuantitativo inmediato sobre el conjunto de las imágenes, además de una sugerencia automática de patrón y una evaluación de calidad [22]. Esta combinación de análisis rápido y control de calidad es especialmente importante en investigación, donde permite comparar bases de datos amplias, detectar centros o lotes con peor calidad relativa y explotar bases de datos extensas, evitando que la revisión manual de imágenes constituya el principal cuello de botella [13, 20, 22].
Una capilaroscopia puede agrupar múltiples imágenes por dedo y devolver un resumen cuantitativo inmediato con sugerencia de patrón y calidad.
Reproducibilidad, validación y sesgos
La variable crítica en IA capilaroscópica no es solo el rendimiento, sino la reproducibilidad del "ecosistema" completo: imagen, quality assessment, etiquetado, algoritmo, informe y contexto clínico [2, 3, 4, 5, 7, 8, 9, 10, 11, 12, 13].
El primer sesgo aparece en la etiqueta, es decir, en la categoría diagnóstica o variable que los expertos asignan a cada imagen para entrenar el modelo. CAPI-Score y CAPI-Detect aprenden a partir de consensos humanos, parciales o completos [8, 9]. Esto significa que el modelo puede refrendar el acuerdo entre expertos sin que necesariamente haya descubierto una verdad biológica distinta. Este matiz no invalida el método, pero sí obliga a interpretar los resultados como ayuda a la clasificación consensuada, no como un sustituto de la medicina clínica.
El segundo sesgo es técnico. Diferencias de magnificación, iluminación, número de dedos, sectores del lecho ungueal, calidad de la primera fila y factores de confusión como cutícula traumática o edema pueden alterar la identificación de variables [2, 7, 11, 12, 13, 24]. Por eso, los consensos recientes insisten en definir dominios de variables mínimos para proporcionar validez al estudio. Así, en 2026 el grupo italiano acordó valorar 23 ítems, y consideró que 16 de ellos eran obligatorios para redactar con garantías el informe rutinario [12]. El conjunto de dominios imprescindibles propuesto en 2024 refuerza la misma idea: si no se armoniza qué se describe, el algoritmo y el lector humano acaban comparando materiales distintos [11]. Lo que intenta el control automático de calidad es, precisamente, evitar este riesgo de partida, y no tanto conseguir una mejora "mágica" del diagnóstico final [13].
El tercer sesgo se localiza en la traslación a la clínica. Un modelo entrenado principalmente para distinguir SSc de no SSc puede rendir muy bien pero, aun así, seguir siendo poco útil en un entorno donde predominan patrones limítrofes, conectivopatías no esclerodérmicas o estudios de mala calidad [8, 9, 10, 14]. El antes citado estudio sobre patrones inespecíficos ilustra bien este problema: incluso con 761 casos y validación cruzada intensiva, el F1-score no pasó de 0,632, y la mayoría de errores consistió en etiquetar enfermedades autoinmunes como Raynaud primario [14]. Por eso, la validación externa no es un "lujo metodológico"; es la condición mínima para proporcionar fiabilidad al software en contextos diferentes del entorno en el que se desarrolló [7].
Integración en la práctica diaria
La pregunta correcta no es solo si la IA "funciona y mejora", sino también dónde encaja sin empeorar el proceso. En un laboratorio o consulta real, la automatización útil es la que ahorra tiempo, reduce variabilidad y permite percibir en qué puntos se sigue necesitando juicio "humano" experto [1, 2, 3, 5, 7, 11, 12, 13].
La integración más razonable puede desglosarse en varias fases. Primera, adquisición. Segunda, quality assessment con feedback inmediato para excluir contenido inválido e identificar imágenes válidas pero subóptimas [13]. Tercera, ayuda a la detección y cuantificación: contar mejor, medir mejor, localizar hemorragias o marcar capilares anómalos [6, 7]. Cuarta, asistencia a la clasificación: proponer, con un grado razonable de confianza, si un estudio sugiere un patrón normal, inespecífico o esclerodermiforme [8, 9, 10, 14]. Quinta, apoyo al informe: completar dominios estructurados y recordar factores de confusión o campos obligatorios con arreglo a los consensos existentes [11, 12].
En clínica, esta dinámica reduce los tiempos muertos. Si un caso estándar consta de 32 imágenes, revisar una a una su calidad, contar capilares y resumir hallazgos puede convertirse en una carga importante incluso para equipos expertos [24]. Si el control de calidad, la cuantificación y el resumen se generan de forma inmediata, el profesional puede dedicar más tiempo a la traslación a la clínica y menos al trabajo repetitivo [13, 22]. La ganancia no es solo en comodidad; también se reduce la tentación de simplificar la adquisición o de analizar menos dedos de los deseables para aliviar la presión asistencial.
En investigación, el impacto puede ser aún mayor. La automatización rápida permite explotar el potencial de colecciones con cientos o miles de capilaroscopias, comparar subgrupos, revisar calidad relativa entre centros y filtrar automáticamente imágenes no válidas antes de entrenar modelos o hacer análisis estadísticos [7, 13, 14, 15, 16, 17, 18, 19, 20, 22]. Cabe entonces concluir que la principal ventaja no es, o no es únicamente, "ir más rápido", sino poder plantear preguntas de investigación que serían inviables si cada imagen tuviera que revisarse y anotarse manualmente desde cero.

Queda patente que lo que todavía no parece admisible es un "autoinforme" clínico completamente ciego a la calidad de la adquisición o al contexto del paciente. Incluso donde el rendimiento es alto, la propia bibliografía reciente sigue manteniendo al observador experto como árbitro final, especialmente en casos con diagnósticos "limítrofes" o cuando las categorías son clínicamente sutiles [5, 8, 9, 10, 12].
| Escenario | Dónde ayuda la IA | Dónde no debería actuar sola |
|---|---|---|
| Consulta con alto volumen de Raynaud | Cribado inicial, control de calidad y recuento estructurado [8, 9, 10, 13, 14] | Diagnóstico final sin correlación clínica |
| Centro experto en esclerosis sistémica | Reducir variabilidad, vigilar calidad y acelerar cuantificación [7, 8, 9, 13] | Reemplazar lectura experta en casos complejos |
| Estudio multicéntrico o registro | Estandarizar medidas, control de calidad y notificación [7, 11, 12, 13] | Combinar datos heterogéneos sin control de calidad |
| Enfermedades no esclerodérmicas | Generar datos cuantitativos exploratorios y probar hipótesis pronósticas [14, 15, 16, 17, 18] | Aplicar modelos entrenados solo en SSc |
Casos clínicos abreviados
Caso 1. Raynaud con imágenes "al límite"
Un centro generalista usa un algoritmo cuantitativo para separar estudios normales de inespecíficos y detectar patrón esclerodermiforme. Antes de clasificar, el módulo de quality assessment identifica varias imágenes por baja magnificación y reflejos. Esta alerta ya es clínicamente útil: obliga a repetir la adquisición antes de aceptar, con garantía insuficiente, un resultado "no esclerodermiforme, patrón inespecífico". La decisión sensata no es aceptar o rechazar el resultado bruto, sino revisar calidad, aplicar Fast Track si procede y correlacionar con serología y evolución clínica [3, 5, 8, 9, 13, 14].
Caso 2. Registro multicéntrico de miopatías inflamatorias
Un proyecto multicéntrico quiere cuantificar hemorragias y densidad en distintos hospitales. Aquí la IA puede aportar más que en consulta individual porque armoniza medidas y reduce la carga de lectura, pero sigue siendo imprescindible fijar protocolo de adquisición, control de calidad y definiciones comunes antes de analizar asociaciones pronósticas. Los datos preliminares de CapIAMI apoyan precisamente este enfoque combinado entre cuantificación automatizada y biomarcadores, más que una sustitución del clínico [11, 12, 13, 15].
FAQ
¿La IA puede sustituir al capilaroscopista experto?
No. Puede contribuir a la detección, cuantificación y clasificación, pero la evidencia actual no respalda sustituir la lectura experta en casos individuales [7, 8, 9, 10, 12].
¿A día de hoy, qué problema resuelve mejor la automatización?
Reducir parte de la variabilidad al detectar capilares, medir dominios estructurados y apoyar la clasificación de patrón esclerodermiforme frente a no esclerodermiforme [3, 6, 7, 8, 9].
¿Dónde sigue fallando más?
En categorías "fronterizas" como patrón normal frente a inespecífico, en imágenes de mala calidad y al trasladar modelos a poblaciones, equipos o centros distintos [5, 7, 8, 9, 10].
¿CAPI-Score y CAPI-Detect son lo mismo?
No. CAPI-Score usa reglas cuantitativas relativamente simples; CAPI-Detect emplea aprendizaje automático con más variables arquitectónicas [8, 9].
¿La plataforma Capillary.io tiene publicaciones revisadas por pares?
Sí, la web de publicaciones de Capillary.io lista trabajos revisados por pares y resúmenes de congresos; aun así, cada estudio debe juzgarse por su diseño, validación y utilidad clínica real, no por la marca de la plataforma [6, 7, 8, 9, 13, 14, 15, 16, 17, 18, 19, 20].
Glosario
- Cuantificación
- Conversión de hallazgos capilaroscópicos en variables medibles, continuas o categóricas, que puedan compararse entre observadores o centros.
- Validación externa
- Evaluación de la validez de un algoritmo empleando datos distintos de los usados para desarrollarlo, idealmente en otros centros, equipos o poblaciones.
- Fast Track
- Algoritmo simplificado propuesto por EULAR para diferenciar de forma rápida patrón esclerodermiforme frente a no esclerodermiforme.
- CAPI-Score
- Algoritmo cuantitativo basado en reglas que clasifica patrones capilaroscópicos a partir de variables como densidad, gigantes, anómalos, tortuosidades y hemorragias.
- CAPI-Detect
- Modelo de aprendizaje automático que incorpora un número mayor de variables arquitectónicas para mejorar la clasificación de patrones capilaroscópicos.
- Quality assessment
- Evaluación automática o manual de si una imagen tiene calidad suficiente para entrar en análisis, incluyendo detección de desenfoque, reflejos, magnificación incorrecta o contenido inválido.
Referencias
- Smith V, Cutolo M, Herrick AL, Ingegnoli F, Ruaro B, Sulli A, et al. Nailfold capillaroscopy. Best Pract Res Clin Rheumatol. 2023;37(1):101849. DOI: 10.1016/j.berh.2023.101849. PMID: 37419757.
- Smith V, Herrick AL, Ingegnoli F, Damjanov N, De Angelis R, Denton CP, et al. Standardisation of nailfold capillaroscopy for the assessment of patients with Raynaud's phenomenon and systemic sclerosis. Autoimmun Rev. 2020;19(3):102458. DOI: 10.1016/j.autrev.2020.102458. PMID: 31927087.
- Smith V, Vanhaecke A, Herrick AL, Distler O, Guerra MG, Denton CP, et al. Fast track algorithm: How to differentiate a "scleroderma pattern" from a "non-scleroderma pattern". Autoimmun Rev. 2019;18(11):102394. DOI: 10.1016/j.autrev.2019.102394. PMID: 31520797.
- Dinsdale G, Murray A, Moore T, Manning J, Wilkinson J, Herrick AL. Intra-and inter-observer reliability of nailfold videocapillaroscopy - A possible outcome measure for systemic sclerosis-related microangiopathy. Microvasc Res. 2017;112:1-6. DOI: 10.1016/j.mvr.2017.02.001. PMID: 28163035.
- Ng SA, Tan WH, Saffari SE, Low AHL. Evaluation of Nailfold Capillaroscopy Online Training Using the Fast Track Algorithm. J Rheumatol. 2023;50(3):368-372. DOI: 10.3899/jrheum.220794. PMID: 36455942.
- Gracia Tello B, Ramos Ibañez E, Fanlo Mateo P, Sáez Cómet L, Martínez Robles E, Ríos Blanco JJ, et al. The challenge of comprehensive nailfold videocapillaroscopy practice: a further contribution. Clin Exp Rheumatol. 2022;40(10):1926-1932. DOI: 10.55563/clinexprheumatol/6usce8. PMID: 34936544.
- Gracia-Tello B, Sáez-Comet L, Lledó G, Freire Dapena M, Guillén del Castillo A, Simeón-Aznar CP, et al. External clinical validation of automated software to identify structural abnormalities and microhaemorrhages in nailfold videocapillaroscopy images. Clin Exp Rheumatol. 2023;41(8):1605-1611. DOI: 10.55563/clinexprheumatol/4y38g6. PMID: 37140670.
- Gracia Tello BC, Sáez Comet L, Lledó G, Freire Dapena M, Mesa MA, Martín-Cascón M, et al. CAPI-Score: a quantitative algorithm for identifying disease patterns in nailfold videocapillaroscopy. Rheumatology (Oxford). 2024;63(12):3315-3321. DOI: 10.1093/rheumatology/keae197. PMID: 38530791.
- Lledó-Ibáñez GM, Sáez Comet L, Freire Dapena M, Mesa Navas M, Martín Cascón M, Guillén Del Castillo A, et al. CAPI-Detect: machine learning in capillaroscopy reveals new variables influencing diagnosis. Rheumatology (Oxford). 2025;64(6):3667-3675. DOI: 10.1093/rheumatology/keaf073. PMID: 39918978.
- Garaiman A, Nooralahzadeh F, Mihai C, Perez Gonzalez N, Gkikopoulos N, Becker MO, et al. Vision transformer assisting rheumatologists in screening for capillaroscopy changes in systemic sclerosis: an artificial intelligence model. Rheumatology (Oxford). 2023;62(7):2492-2500. DOI: 10.1093/rheumatology/keac541. PMID: 36347487.
- El Miedany Y, Ismail S, Wadie M, Müller-Ladner U, Giacomelli R, Liakouli V, et al. Development of a core domain set for nailfold capillaroscopy reporting. Reumatol Clin (Engl Ed). 2024;20(7):345-352. DOI: 10.1016/j.reumae.2024.07.003. PMID: 39160005.
- Ingegnoli F, Pireddu D, Platania E, De Angelis R, Alunno A, Ariani A, et al. Clinical practice guidelines for reporting nail fold videocapillaroscopy: a Delphi consensus on behalf of the Italian Society of Rheumatology study group on capillaroscopy. Clin Exp Rheumatol. 2026 Jan 15. Online ahead of print. DOI: 10.55563/clinexprheumatol/2z4j95. PMID: 41537537.
- Gracia Tello B, Lledó Ibáñez G, Sáez Comet L, Ramos ibáñez E. Automated Feedback and Quality Control in Nailfold Capillaroscopy: A Tool for Clinical and Educational Use [abstract]. Arthritis Rheumatol. 2025;77(suppl 9). Disponible en: https://acrabstracts.org/abstract/automated-feedback-and-quality-control-in-nailfold-capillaroscopy-a-tool-for-clinical-and-educational-use/
- Maldonado G, Marin Ballve A, Sáez Comet L, Freire Dapena M, Mesa M, Martín Cascón M, et al. Machine Learning-Based Classification of Raynaud’s Phenomenon and Autoimmune Diseases in Indeterminate Capillaroscopic Patterns [abstract]. Arthritis Rheumatol. 2025;77(suppl 9). Disponible en: https://acrabstracts.org/abstract/machine-learning-based-classification-of-raynauds-phenomenon-and-autoimmune-diseases-in-indeterminate-capillaroscopic-patterns/
- Lledó Ibáñez G, Álvarez-Troncoso J, Gracia Tello B, Prieto-Gonzalez S, Martínez Robles E, Cristina-Varela D, et al. Artificial Intelligence-Based Capillaroscopy and Laboratory Biomarkers to Predict Disease Activity in Idiopathic Inflammatory Myopathies: Preliminary Data from the CapIAMI Cohort [abstract]. Arthritis Rheumatol. 2025;77(suppl 9). Disponible en: https://acrabstracts.org/abstract/artificial-intelligence-based-capillaroscopy-and-laboratory-biomarkers-to-predict-disease-activity-in-idiopathic-inflammatory-myopathies-preliminary-data-from-the-capiami-cohort/
- Carrillo M, Bedoya-Loaiza J, Ibáñez-Antequera C, Gallego L, Escobar A, Rojas-Villarraga A, et al. Capillaroscopic Signatures in Autoimmune Rheumatic Diseases: Unveiling Patterns in Systemic Sclerosis, Polyautoimmunity, and PAH [abstract]. Arthritis Rheumatol. 2025;77(suppl 9). Disponible en: https://acrabstracts.org/abstract/capillaroscopic-signatures-in-autoimmune-rheumatic-diseases-unveiling-patterns-in-systemic-sclerosis-polyautoimmunity-and-pah/
- Zheng Z, Metni L, Kim S, Neely J. Evaluating Nailfold Capillary Changes as Indicators of Disease Activity in Juvenile Dermatomyositis [abstract]. Arthritis Rheumatol. 2025;77(suppl 9). Disponible en: https://acrabstracts.org/abstract/evaluating-nailfold-capillary-changes-as-indicators-of-disease-activity-in-juvenile-dermatomyositis/
- McClellan N, Vandenbergen S, Matossian S, Kahlenberg J, Turnier J. Differences in Nailfold Capillary Morphology Distinguish Juvenile Dermatomyositis Patients That Are Myositis-Specific Autoantibody Positive [abstract]. Arthritis Rheumatol. 2023;75(suppl 9). Disponible en: https://acrabstracts.org/abstract/differences-in-nailfold-capillary-morphology-distinguish-juvenile-dermatomyositis-patients-that-are-myositis-specific-autoantibody-positive/
- Capillary.io. Publicaciones. Capillary.io; acceso 9 de marzo de 2026. Disponible en: https://es.capillary.io/publicaciones/
- Capillary.io. Proyectos de investigación: CapIAMI. Capillary.io; acceso 9 de marzo de 2026. Disponible en: https://es.capillary.io/investigacion/
- Tanidir IC, Caglayan D, Delen Y, Kokturk F, Demirkol S, Cicek OF, et al. Deep Learning Performance in Analyzing Nailfold Videocapillaroscopy Images in Systemic Sclerosis. Diagnostics (Basel). 2025;15(2):205. DOI: 10.3390/diagnostics15020205. PMID: 41300936.
- Sekiyama JY, Camargo CZ, Eduardo L, Andrade CR, Kayser C. Reliability of widefield nailfold capillaroscopy and video capillaroscopy in the assessment of patients with Raynaud’s phenomenon. Arthritis Care Res (Hoboken). 2013;65(11):1853-1861. DOI: 10.1002/acr.22054. PMID: 23754794.
- Capillary.io. Funcionalidades de Capillary.io. Capillary.io; acceso 9 de marzo de 2026. Disponible en: https://es.capillary.io/funcionalidades/
- Guillén del Castillo A, Lledó-Ibáñez GM, Sáez Comet L, Freire Dapena M, Mesa Navas M, Martín Cascón M, et al. Value of nailfold capillaroscopy in the classification of the systemic sclerosis pattern. Med Clin (Barc). 2026;166:107426. DOI: 10.1016/j.medcli.2026.107426. PMID: 42013567.